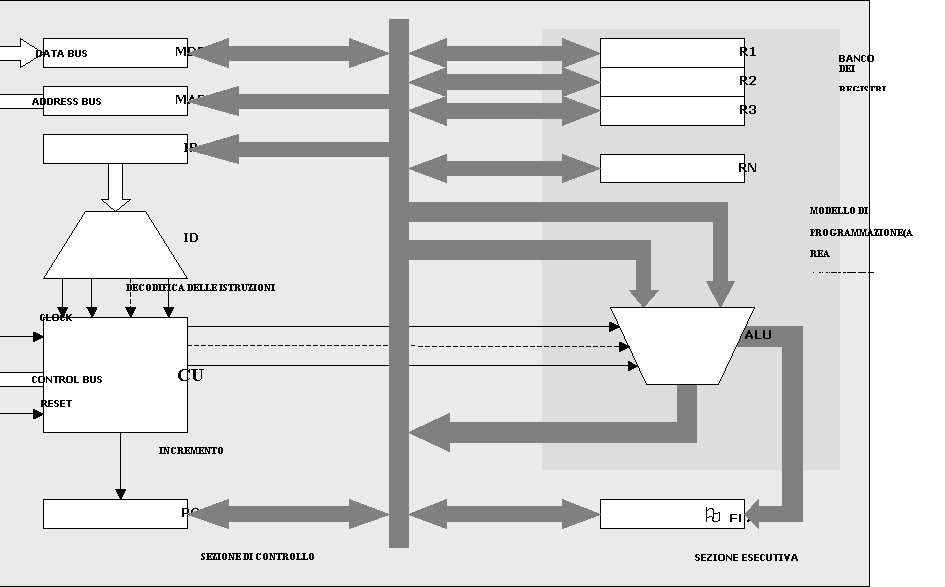
La figura precedente mostra la struttura di principio di un microprocessore. Come si può notare essa si compone di più sottosistemi collegati da un bus interno. Questo bus consente lo scambio delle informazioni fra i vari sottosistemi e si interfaccia con il bus indirizzi ed il bus dati esterni mediante due registri tampone detti rispettivamente MAR (Memory Address Register) e MDR (Memory Data Register). Questi registri conservano gli indirizzi ed i dati da scambiare con l’esterno e sono invisibili al programmatore nel senso che questo non ne può influenzare il comportamento mediante l’esecuzione di istruzioni. Nella parte sinistra della figura è poi simboleggiato il cervello del microprocessore che è l’unità di controllo ed esecuzione. Tale unità si compone del registro IR nel quale viene depositato il codice operativo dell’istruzione prelevato dalla memoria (è quella parte dell’istruzione che dice cosa occorre fare). Il codice operativo è, come ogni dato elaborato dal microprocessore, una stringa di bit che va interpretata per comprendere quali operazioni vengono richieste al microprocessore. A tale scopo viene passato al blocco ID (Instruction Decoder) il quale decodifica l’istruzione e passa l’informazione alla unita di controllo (Control Unit CU) che si occupa di generare i segnali di controllo che costringono le varie unità del microprocessore a cooperare per eseguire l’istruzione.
Per poter operare il microprocessore ha poi bisogno di aree in cui memorizzare le informazioni: i registri.
Il termine registro indica un blocco di memoria, equivalente nella sua struttura ad una cella di memoria ma contenuto all’interno della CPU. Le dimensioni (in bit) dipendono dal tipo di CPU.
La funzione dei registri è di realizzare una memorizzazione temporaneo di una informazione, per il solo tempo necessario per portare a termine l’operazione in cui l’informazione è coinvolta. Si può quindi immaginare un registro come una lavagna su cui viene scritta una informazione per la durata della loro spiegazione e poi viene cancellata quando si passa alla spiegazione successiva; se si vuole che l’informazione sia conservata permanentemente è necessario salvarla da qualche altra parte.
Diversamente dalle celle di memoria i registri non hanno un indirizzo (non sono in memoria centrale ma dentro alla CPU); sono invece identificati da un nome. Alcuni registri sono accessibili al programmatore attraverso il loro nome mentre altri sono invisibili e servono per attuare le azioni di controllo.
Alcuni registri sono specializzati, cioè svolgono solo una specifica funzione mentre altri sono di uso generale, possono cioè essere usati dal programmatore per un qualsiasi scopo.
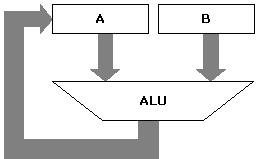
Arithmetic Logic Unit: è il blocco che esegue le trasformazioni sui dati eseguendo operazioni logiche (AND, OR, XOR) e d aritmetiche (somma, sottrazione, confronto, ecc.). Poiché i dati, indipendentemente dal loro significato sono codificati attraverso numeri binari qualsiasi trasformazione da fare sui dati si riduce ad una operazione aritmetica o logica. Opera su due operandi che possono essere contenuti nei registri interni o provenire dalla memoria.
La ALU si comporta in genere da “operatore binario ad
accumulo”. Il termine “binario” in questo caso non sta ad indicare che i dati
sono in codice binario ma che la ALU esegue le operazioni a partire da due
operandi. Il termine “accumulo” sta ad indicare che il risultato
dell’operazione va a finire in uno dei due operandi. In questo modo
nell’operando che è dapprima origine e poi destinazione dei dati si forma un
accumulo di dati.
|
|
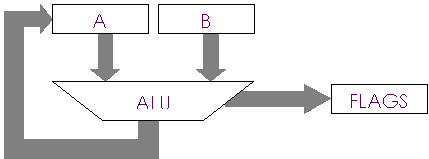
Oltre al risultato
della operazione la ALU produce anche altre informazioni logiche dette FLAGS.
Queste informazioni formano un pacchetto di bit che riflettono con il loro
stato informazioni sul risultato della ultima operazione aritmetico logica
eseguita.
Quindi questi bit si
aggiornano ad ogni operazione aritmetico/logica mentre restano inalterati al
valore della ultima operazione aritmetico/logica mentre la CPU fa altri tipi di
operazione che non coivolgono la ALU (ad esempio trasferimenti sul bus).
Queste informazioni
sono essenziali per la costruzione degli algoritmi dei programmi. Infatti
spesso il programma deve fare delle scelte in funzione dei risultati che si
sono avuti. Il programma deve trovare allora il modo di verificare cosa è
successo durante le elaborazioni precedenti e ciò avviene interrogando il
registro dei flag.
Lo schema completo
della ALU quindi diventa:
|
|
I principali flags
sono:
![]() ZERO (ZF): è vero quando il risultato
dell’ultima operazione vale 0 mentre è falso quando il risultato dell’operazione
è diverso da 0. E’ il flag più usato.
ZERO (ZF): è vero quando il risultato
dell’ultima operazione vale 0 mentre è falso quando il risultato dell’operazione
è diverso da 0. E’ il flag più usato.
![]() CARRY (CF): è vero quando c’è stato un riporto
dal bit più significativo del risultato. Le operazioni di somma e le
operarazioni derivate da questa (sottrazione, moltiplicazione ...) possono
determinare un riporto da un bit al bit
di peso successivo (vedere FULL ADDER). Se la somma del bit più significativo
determina un riporto questo bit non può essere sommato al bit successivo e
viene memorizzato nel CF per segnalare che l’operazione nel suo complesso ha
determinato un riporto.
CARRY (CF): è vero quando c’è stato un riporto
dal bit più significativo del risultato. Le operazioni di somma e le
operarazioni derivate da questa (sottrazione, moltiplicazione ...) possono
determinare un riporto da un bit al bit
di peso successivo (vedere FULL ADDER). Se la somma del bit più significativo
determina un riporto questo bit non può essere sommato al bit successivo e
viene memorizzato nel CF per segnalare che l’operazione nel suo complesso ha
determinato un riporto.
![]() SIGN (SF): è vero quando il risultato è negativo.
Materialmente viene riportato nel SF il bit più significativo del risultato che
riflette il segno.
SIGN (SF): è vero quando il risultato è negativo.
Materialmente viene riportato nel SF il bit più significativo del risultato che
riflette il segno.
![]() OVERFLOW(OF):
è vero se il segno del risultato discorda dal segno degli operandi. Segnala la
presenza di un overflow rispetto alla precisione; infatti se si sommano due
operandi positivi il risultato dovrebbe essere sempre positivo, se il bit più
significativo del risultato è negativo significa che il risultato ha
un’ampiezza superiore alla capacità del risultato; la stessa cosa vale per due
numeri negativi mentre se i due numeri hanno segni discordi un overflow non si
può verificare quindi OF diventa sempre falso.
OVERFLOW(OF):
è vero se il segno del risultato discorda dal segno degli operandi. Segnala la
presenza di un overflow rispetto alla precisione; infatti se si sommano due
operandi positivi il risultato dovrebbe essere sempre positivo, se il bit più
significativo del risultato è negativo significa che il risultato ha
un’ampiezza superiore alla capacità del risultato; la stessa cosa vale per due
numeri negativi mentre se i due numeri hanno segni discordi un overflow non si
può verificare quindi OF diventa sempre falso.
Program Counter: è un registro interno, che contiene in ogni fase di avanzamento del programma l’indirizzo di memoria in cui si trova la prossima istruzione da eseguire.
Viene incrementato automaticamente dalla CU (Control Unit) ogni volta che l’esecuzione di una istruzione è completata in modo da potere leggere in memoria l’istruzione successiva.
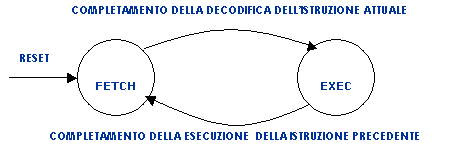
Per comprendere il funzionamento della CPU conviene partire da una automa a stati finiti molto semplice formato da due soli stati: FETCH ed EXECUTE.
|
|
Si può immaginare la CPU come un automa a stati finiti che si muove continuamente tra i due suoi stati:
FETCH (INTERPRETAZIONE): Supponendo che PC stia puntando al codice operativo di una istruzione memorizzato in memoria centrale la CU comanda, attraverso i bus, la lettura dalla memoria del codice operativo (OPCODE) della istruzione; questa informazione attraverso il MDR arriva all’ IR che lo manda al circuito di decodifica ID per ottenere la decodifica della istruzione. Inoltre CU incrementa il PC in modo che al prossimo FETCH punti all’istruzione successiva e passa allo stato di EXECUTE.
EXECUTE (ESECUZIONE): Si entra in stato EXECUTE con l’evento “Completamento della decodifica della istruzione attuale”. Ottenuta la decodifica dell’istruzione la CU comanda ad ALU la parte esecutiva che può coinvolgere sia trasferimenti di bus (lettura di dati dalla memoria, scrittura di dati in memoria, acquisizione di dati dall’ingresso, emissione di dati sull’uscita) in cui l’altro estremo del trasferimento è un registro interno della CPU sia elaborazioni interne fra registri eseguite dalla ALU che portano a risultati memorizzati sui registri. Esistono anche elaborazioni miste che coinvolgono contemporaneamente entrambe le attività (ad esempio una somma tra il contenuto di un registro ed il contenuto di una cella di memoria che viene reso disponibile sul MDR mediante una lettura con risultato in un registro). Al termine della esecuzione l’automa si riporta in FETCH per interpretare l’istruzione successiva il cui indirizzo si trova in PC.