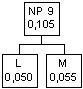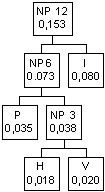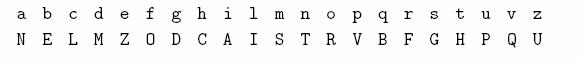Il Livello di
presentazione
La codifica dei
dati
Scopo fondamentale del
livello di presentazione è quello di permettere di dialogare a computer che
usano codifiche diverse per rappresentare i dati.
Se un computer dovesse
inviare dati ad un altro computer che usa codifiche diverse, il trasmettitore
dovrebbe trasformare i dati codificandoli nel formato utilizzato dal computer
ricevitore prima di spedirli. Questa soluzione prevede che un computer, per
dialogare con tutti i computer presenti nella rete, deve conoscere tutti i loro
sistemi i codifica.
Si potrebbe pensare alla
soluzione in cui è il computer ricevente ad occuparsi della transcodifica dei
dati ricevuti nel formato che egli utilizza. In questo caso è il computer
ricevente a dover conoscere tutti i tipi di codifica utilizzati nella rete cui
esso è collegato.
La soluzione ottimale è
che, a livello di sessione sia stabilita una sorta di codifica universale o
codifica di riferimento e che ogni computer ricevente deve trasformare i suoi
dati secondo questa codifica prima di inviarli, ed il computer ricevente li
debba trasformare dal codice di riferimento nel proprio codice. Con questa
soluzione tutti i computer devono conoscere soltanto il proprio sistema di
codifica e quello di riferimento.
La compressione
dei dati.
Il livello di sessione si
occupa anche del problema di comprimere i dati in modo da ridurre i tempi di
trasmissione.
Un primo caso è quello in
cui i dati appartengano ad un insieme di valori finiti, che hanno tutti la
stessa probabilità di essere trasmessi.
Un esempio potrebbe essere
quello di una filiale di una ditta commerciale che deve trasmettere ogni giorno
alla sede centrale il codice dell’articolo venduto in ogni transazione.
Supponiamo che siano venduti 100000 articoli al giorno e che il codice id ogni
articolo sia formato da 13 byte (dimensione del codice a barre). In questo caso
dovranno essere trasmessi 100.000*13=1.300.000 byte per fornire informazioni sui
prodotti venduti ogni giorno. Supponiamo ora che il numero di articoli
possibili nel catalogo della ditta sia
di 10.000. La soluzione più semplice, in luogo di trasmettere il codice
a barre del prodotto, è quella di identificare ogni articolo con un numero
intero. Per rappresentare 10.000 articoli occorrono dunque gli interi da
Un caso diverso è quello
della trasmissione di simboli non equiprobabili, cioè di simboli la cui
probabilità non è identica, come nel caos di un testo scritto in cui le varie
lettere dell’alfabeto non hanno la stessa probabilità. In tal caso si usano
tecniche in cui il codice usato per rappresentare il simbolo è tanto più corto
quanto maggiore è la probabilità che il simbolo debba essere trasmesso.
Tecnica di
Huffmann
Un esempio è la tecnica di
Huffman. Per prima cosa occorre possedere una tabella in cui sia indicata la
probabilità di ogni simbolo
|
Simbolo |
Probabilità |
|
A |
0,129 |
|
B |
0,040 |
|
C |
0,047 |
|
D |
0,029 |
|
E |
0,088 |
|
F |
0,023 |
|
G |
0,032 |
|
H |
0,018 |
|
I |
0,080 |
|
L |
0,050 |
|
M |
0,055 |
|
N |
0,056 |
|
O |
0,100 |
|
P |
0,035 |
|
Q |
0,008 |
|
R |
0,060 |
|
S |
0,070 |
|
T |
0,044 |
|
U |
0,012 |
|
V |
0,020 |
|
Z |
0,004 |
|
Probabilità
totale |
1 |
Mettiamo i simboli in
ordine crescente di probabilità
|
Simbolo |
Probabilità |
|
Z |
0,004 |
|
Q |
0,008 |
|
U |
0,012 |
|
H |
0,018 |
|
V |
0,020 |
|
F |
0,023 |
|
D |
0,029 |
|
G |
0,032 |
|
P |
0,035 |
|
B |
0,040 |
|
T |
0,044 |
|
C |
0,047 |
|
L |
0,050 |
|
M |
0,055 |
|
N |
0,056 |
|
R |
0,060 |
|
S |
0,070 |
|
I |
0,080 |
|
E |
0,088 |
|
O |
0,100 |
|
A |
0,129 |
|
Probabilità
totale |
1 |
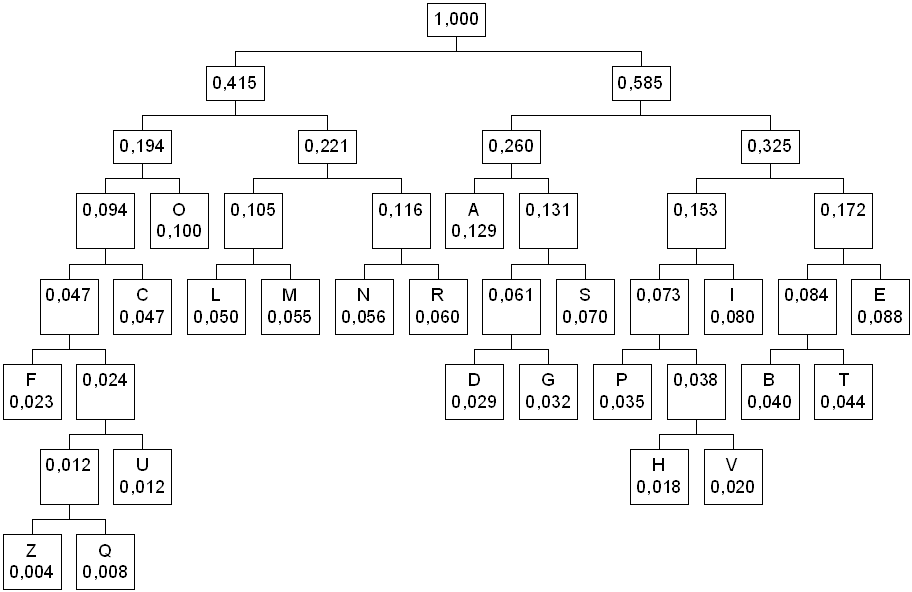
A questo punto si costruisce
un albero delle probabilità secondo il seguente algoritmo: si scorrono i
simboli a partire da quelli a
probabilità inferiore; se trovo due simboli che hanno una probabilità inferiore
a nodi già presenti nell’albero, costruisco un nuovo nodo a cui unisco i due nodi suddetti come foglie
ed associo al nuovo nodo una probabilità data dalla somma delle probabilità dei
due simboli. Se trovo un solo simbolo a probabilità inferiore ad uno dei nodi
già presenti nell’albero, unisco il simbolo e tale nodo come foglie di un nuovo
nodo che avrà ancora come probabilità la somma delle probabilità delle due
foglie.
Esemplifichiamo con le
probabilità della tabella di esempio.
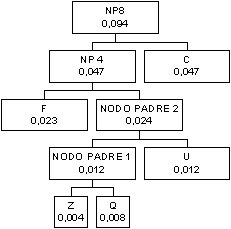
Si scelgono i due simboli
che secondo la tabella hanno probabilità minore, in questo caso Z e Q

I due nodi vengono uniti
ad un nodo padre la cui probabilità è la somma delle probabilità dei nodi figli
cioè 0,004+0,008 = 0,012
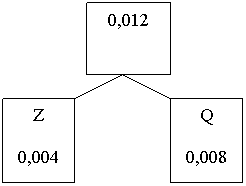
Ora, guardando la tabella si
nota che tutti i simboli hanno una probabilità superiore a quella di questo
nodo padre tranne il simbolo U che ha la stessa probabilità, allora U diventa
un nodo dell’albero e viene unito insieme a tale nodo ad un nuovo nodo padre
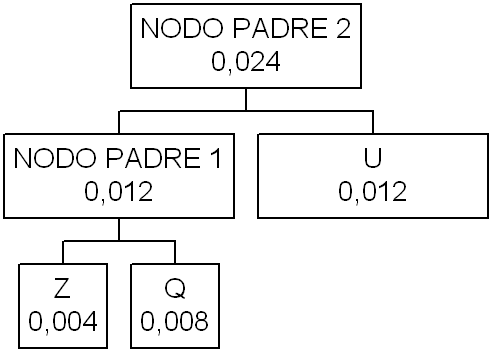
Il nuovo nodo padre è
caratterizzato da una probabilità complessiva di 0,024. scorrendo la tabella si
nota che i caratteri H e V hanno entrambi probabilità inferiore a quella del
nodo padre appena inserito per cui vanno collegati ad un nuovo nodo padre
differente dal precedente

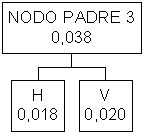
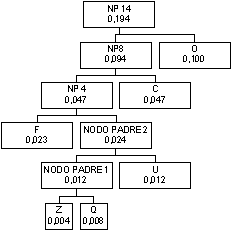
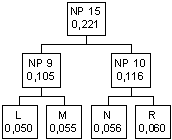
Se ora guardiamo alla
tabella abbiamo che il carattere F ha probabilità 0,023, poi viene il nodo
padre 2 con probabilità 0,024, poi il nodo D con probabilità maggiore a quella del
nodo padre 2, per cui vanno uniti F ed il nodo padre 2 ad un nuovo nodo padre
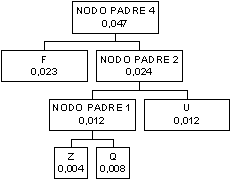

I nodi D e G hanno
probabilità inferiore a quella di tutti i caratteri rimanenti e dei nodi padri introdotti
per cui vanno collegati ad un nuovo nodo padre

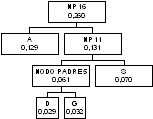
Fra i caratteri rimanenti
quello con probabilità inferiore ora è P(0,035) poi viene il nodo padre 3
(0,038). Essi vanno perciò uniti in un nuovo nodo padre
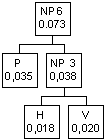
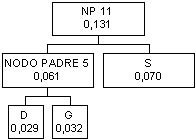
I nodi B (0,040) e T
(0,044) hanno probabilità inferiore a quella dei nodi padri 4, 5 e 6 per cui
vanno collegati ad un nuovo nodo padre
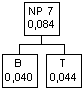
IL carattere C ha
probabilità 0,47, il carattere L viene subito dopo con probabilità 0,050, che è
superiore a quella del nodo padre 4 (0.047) per cui vanno collegati C e il nodo
padre 4 ad un nuovo nodo padre
L (0,050) e M (0,055) hanno
probabilità inferiore a quella di tutti i nodi padri, per cui vanno collegati
ad un nuovo nodo padre indipendente