Stack e nidificazione dei sottoprogrammi
La chiamata di un sottoprogramma
Il nesting dei sottoprogrammi.
Stack e nidificazione dei sottoprogrammi
Cos’è un sottoprogramma?
Nella
programmazione è frequente il ricorso all’utilizzo di sottoprogrammi. Vediamo
cos’è un sottoprogramma. Facciamolo con un esempio. Supponiamo di voler
scrivere un programma che si occupi di risolvere una equazione di secondo grado
con la formula
![]()
Occupiamoci della
parte del programma che si occupa del calcolo del delta. Supponiamo in
particolare che stiamo scrivendo il programma in assembly per un
microprocessore generico che abbia una serie di registri di utilizzo generale
denominati da A a G, che questo microprocessore comprenda istruzioni tipo
LEGGI, SPOSTA e così via e che ogni istruzione si traduca in una stringa di bit
di lunghezza pari a quella delle locazioni di memoria utilizzate dal
microprocessore. Supponiamo inoltre che i parametri dell’equazione a, b, c
siano conservati già nei registri del microprocessore denominati C, D, E. il
programma per il calcolo del delta sarà allora il seguente
- COPIA IL
CONTENUTO DI D IN A [1]
- COPIA A IN B[2]
- DEC B[3]
- COPIA A IN F [4]
- SOMMA A,F
- DECREMENTA B[5]
- SE B <> 0
TORNA ALL’ISTRUZIONE 5[6]
- COPIA A IN G[7]
- COPIA C IN A[8]
10.
COPIA E IN B[9]
- DEC B
- COPIA A IN F
- SOMMA A,F
- DECREMENTA B
- SE B <> 0
TORNA ALL’ISTRUZIONE 13 [10]
- COPIA 4 IN B
- DEC B
- COPIA A IN F
- SOMMA A,F
- DECREMENTA B
- SE B
<> 0 TORNA ALL’ISTRUZIONE 19
Notate ora che nel programma
abbiamo dovuto risolvere per tre volte il problema della moltiplicazione, per
cui, al di là delle istruzioni che ci consentivano di selezionare gli operandi
della moltiplicazione ( e che ho evidenziato in grassetto) ci sono alcune
istruzioni (in corsivo sottolineato) che si ripetono sempre.
Immaginiamo di prendere queste
istruzioni e racchiuderle in un programma a parte
- DEC B ;
sottoprogramma MOLTIPLICA
- COPIA A IN F
- SOMMA A,F
- DECREMENTA B
- SE B <> 0
TORNA ALL’ISTRUZIONE 3
Abbiamo costruito un programma che effettua
il prodotto fra il numero presente nel registro A e il numero presente nel
registro B.
L’idea è ora la seguente: quando un
programma si trova di fronte al compito di effettuare la moltiplicazione, in
luogo di svilupparla direttamente farà riferimento al programma MOLTIPLICA,
affidando ad esso tale compito. Il programma principale si deve soltanto
occupare di porre un moltiplicando nel registro A ed uno nel registro B. Se
disponiamo di un’istruzione del tipo CHIAMA sottoprogramma il programma principale
diventa semplicemente
- COPIA IL CONTENUTO
DI D IN A
- COPIA A IN B
- CHIAMA MOLTIPLICA
- COPIA A IN G
- COPIA C IN A
- COPIA E IN B
- CHIAMA MOLTIPLICA
- COPIA 4 IN B
- CHIAMA MOLTIPLICA
Vediamo che
abbiamo tutta una serie di vantaggi
![]() Il programma principale è più semplice
Il programma principale è più semplice
![]() Se ho già una volta affrontato il problema risolto
dal sottoprogramma (nell’esempio la moltiplicazione fra due numeri) non devo
risolverlo di nuovo ma applicare nel programma principale il sottoprogramma che
ho scritto precedentemente
Se ho già una volta affrontato il problema risolto
dal sottoprogramma (nell’esempio la moltiplicazione fra due numeri) non devo
risolverlo di nuovo ma applicare nel programma principale il sottoprogramma che
ho scritto precedentemente
![]() Il programma principale è più corto ed occupa uno
spazio minore in memoria
Il programma principale è più corto ed occupa uno
spazio minore in memoria
![]() Lo sviluppo di un programma può essere
modularizzato: una persona si può occupare del programma principale e lasciare ad altri lo sviluppo dei
sottoprogrammi
Lo sviluppo di un programma può essere
modularizzato: una persona si può occupare del programma principale e lasciare ad altri lo sviluppo dei
sottoprogrammi
La chiamata di un sottoprogramma
Ma come avviene la chiamata di un sottoprogramma? E’ difficile pensare che il programma principale chiami il sottoprogramma telefonandogli o mandandogli un telegramma.
Dobbiamo ricordare che le varie istruzioni sono racchiuse in locazioni di memoria
|
100 |
COPIA IL CONTENUTO DI D IN A |
|
101 |
COPIA A IN B |
|
102 |
CHIAMA MOLTIPLICA |
|
103 |
COPIA A IN G |
|
104 |
COPIA C IN A |
|
105 |
COPIA E IN B |
|
106 |
CHIAMA MOLTIPLICA |
|
107 |
COPIA 4 IN B |
|
108 |
CHIAMA MOLTIPLICA |
Nell’ipotesi che ogni istruzione occupi esattamente una locazione di memoria la situazione è quella rappresentata nella tabella precedente dove abbiamo supposto che il programma occupi 9 locazioni di memoria a partire dall’indirizzo 100. il sottoprogramma MOLTIPLICA si troverà invece in un’altra zona di memoria a partire dall’indirizzo 200 (è un esempio).
|
200 |
DEC B |
|
201 |
COPIA A IN F |
|
202 |
SOMMA A,F |
|
203 |
DECREMENTA B |
|
204 |
SE B <> 0 TORNA ALL’ISTRUZIONE 3 |
Il programma principale viene svolto nella giusta sequenza grazie al Program Counter che, in ogni fase di fetch dell’istruzione, si incrementa automaticamente di 1.
Quando il PC conterrà l’indirizzo 102 verrà effettuato il fetch dell’istruzione CHIAMA MOLTIPLICA, automaticamente il PC si incrementa al valore 103. Cosa deve avvenire nella fase di esecuzione? Se ci pensiamo bene, chiamare il sottoprogramma significa semplicemente che non deve essere prelevata l’istruzione all’indirizzo 103 ma quella all’indirizzo 200, e continuare ad eseguire le istruzioni da questo punto in poi della memoria. Quindi l’istruzione CHIAMA non deve far altro che sostituire, all’interno del PC l’indirizzo 103 con l’indirizzo 200.
C’è però un particolare: quando termina l’esecuzione del programma MOLTIPLICA, si deve ritornare al programma principale dall’indirizzo 103 in poi.
Ogni sottoprogramma termina con un’istruzione di RITORNO che deve garantire il ritorno corretto all’esecuzione della parte restante del programma principale. Ciò avviene perché l’indirizzo che era contenuto nel PC, prima dell’esecuzione del salto, (nel nostro esempio 103) viene salvato in una zona di memoria detta STACK[11], prima di essere sostituito dall’indirizzo della prima istruzione del sottoprogramma (nel nostro esempio 200). L’istruzione RITORNO deve, invece, prelevare l’indirizzo di rientro dallo STACK e inserirlo nel PC. In tal modo, in maniera automatica il microprocessore tornerà ad eseguire il programma principale.
Lo stack
Lo stack è un’area di memoria particolare ricavata nella RAM collegata al microprocessore.
In generale le memorie RAM hanno una organizzazione di tipo ad accesso casuale. Questa dizione sta a significare che il microprocessore può accedere (leggere o scrivere) a qualunque locazione della memoria senza limiti.
Lo stack ha invece un’organizzazione detta LIFO (last in first out: l’ultimo ad entrare è il primo ad uscire). Il microprocessore, in tal caso, non può accedere ad una qualunque delle locazioni di memoria dello stack, ma può soltanto accedere alla cima dello stack. Immaginatevi, ad esempio, una catasta di libri: non potete tirare un libro dal centro della catasta, ma potete prendere soltanto quello che si trova in cima così come potete depositarne uno soltanto in cima alla catasta.
Supponiamo, ad esempio, uno stack costituito da 5 locazioni, e che esso sia inizialmente vuoto, a partire dall’indirizzo 100.
|
Indirizzo |
Locazione |
|
100 |
Vuoto |
|
101 |
Vuoto |
|
102 |
Vuoto |
|
103 |
Vuoto |
|
104 |
Vuoto |
Se inseriamo un dato, esso verrà necessariamente posto nella cima dello stack che è la locazione 104[12]
|
Indirizzo |
Locazione |
|
100 |
Vuoto |
|
101 |
Vuoto |
|
102 |
Vuoto |
|
103 |
Vuoto |
|
104 |
Primo dato |
La locazione 104 viene detta cima dello stack. Se inseriamo un secondo dato, esso va posto necessariamente nella locazione che viene subito sopra cioè la 103
|
Indirizzo |
Locazione |
|
100 |
Vuoto |
|
101 |
Vuoto |
|
102 |
Vuoto |
|
103 |
Secondo dato |
|
104 |
Primo dato |
Adesso la cima dello stack è la locazione 103.
Se inseriamo un terzo dato, esso dovrà essere inserito necessariamente nella locazione 102
|
Indirizzo |
Locazione |
|
100 |
Vuoto |
|
101 |
Vuoto |
|
102 |
Terzo dato |
|
103 |
Secondo dato |
|
104 |
Primo dato |
Quando vogliamo prelevare dati, invece, possiamo soltanto prelevare il dato in cima allo stack (nell’esempio il contenuto della locazione 103): non possiamo accedere, ad esempio, alla locazione 103 o 104. Dopo il prelievo la situazione è la seguente
|
Indirizzo |
Locazione |
|
100 |
Vuoto |
|
101 |
Vuoto |
|
102 |
Vuoto
|
|
103 |
Secondo dato |
|
104 |
Primo dato |
La cima dello stack è ora la 103. Soltanto adesso possiamo prelevare il secondo dato. In ogni caso non possiamo accedere alla locazione 104. Soltanto se preleviamo il secondo dato possiamo accedere al primo dato.
|
Indirizzo |
Locazione |
|
100 |
Vuoto |
|
101 |
Vuoto |
|
102 |
Vuoto |
|
103 |
Vuoto |
|
104 |
Primo dato |
Il nesting dei sottoprogrammi.
Perché abbiamo bisogno di una struttura come lo stack? Esso è necessario per realizzare il nesting o nidificazione dei sottoprogrammi.
Questo concetto significa semplicemente che spesso un programma chiama un sottoprogramma ma questi, a sua volta, per l’esecuzione di compiti specifici chiama un altro sottoprogramma.
Ad esempio, il programma che risolve l’equazione di secondo grado chiama un sottoprogramma che fa la radice quadrata del delta
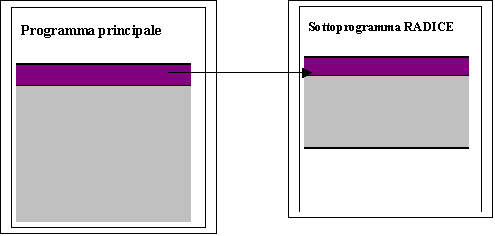
Il sottoprogramma radice chiama a sua volta il sottoprogramma che calcola il delta
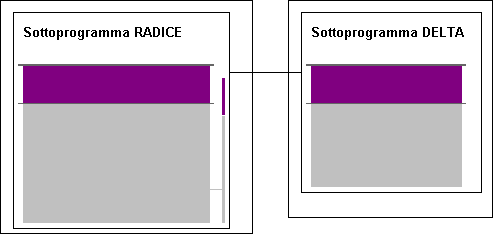
Il sottoprogramma delta può chiamare un altro sottoprogramma, ecc.
Il problema del nesting dei sottoprogrammi è che si deve poter ritornare indietro nell’ordine giusto. Supponiamo di aver questo caso

Quando il terzo sottoprogramma termina occorre che il controllo passi al secondo sottoprogramma; quando questo termina occorre passare a completare il primo e soltanto quando questo termina si passa a terminare il programma principale

Ciò è garantito da un meccanismo automatico basato sullo stack. Infatti quando si passa dal programma principale al primo sottoprogramma, l’indirizzo di rientro del programma principale viene salvato nello stack
Tabella 1
|
Indirizzo |
Locazione |
|
100 |
Vuoto |
|
101 |
Vuoto |
|
102 |
Vuoto
|
|
103 |
Vuoto
|
|
104 |
Indirizzo di rientro del programma principale |
Quando il primo sottoprogramma chiama il secondo sottoprogramma, nello stack viene salvato l’indirizzo di rientro del primo sottoprogramma
Tabella 2
|
Indirizzo |
Locazione |
|
100 |
Vuoto |
|
101 |
Vuoto |
|
102 |
Vuoto
|
|
103 |
Indirizzo di rientro del primo sottoprogramma
|
|
104 |
Indirizzo di rientro del programma principale |
Quando il secondo sottoprogramma chiama il secondo sottoprogramma, nello stack viene salvato l’indirizzo di rientro del secondo sottoprogramma
Tabella 3
|
Indirizzo |
Locazione |
|
100 |
Vuoto |
|
101 |
Vuoto |
|
102 |
Indirizzo di rientro del secondo sottoprogramma
|
|
103 |
Indirizzo di rientro del primo sottoprogramma
|
|
104 |
Indirizzo di rientro del programma principale |
IL terzo sottoprogramma termina con un’istruzione di ritorno, quest’ultima non fa nient’altro che accedere alla cima dello stack , prelevarne il contenuto e metterlo nel Program Counter. Automaticamente si ritorna ad eseguire il secondo sottoprogramma. Però poiché si è effettuato un prelievo dallo stack, la cima dello stack si è spostata all’indirizzo 103
|
Indirizzo |
Locazione |
|
100 |
Vuoto |
|
101 |
Vuoto |
|
102 |
Vuoto
|
|
103 |
Indirizzo di rientro del primo sottoprogramma
|
|
104 |
Indirizzo di rientro del programma principale |
Quando termina il secondo sottoprogramma, viene eseguita di nuovo un’istruzione di ritorno, la quale va in cima allo stack e automaticamente preleva l’indirizzo di rientro del primo sottoprogramma. Ora la cima dello stack è la locazione 103
|
Indirizzo |
Locazione |
|
100 |
Vuoto |
|
101 |
Vuoto |
|
102 |
Vuoto
|
|
103 |
Vuoto
|
|
104 |
Indirizzo di rientro del programma principale |
Al termine del primo sottoprogramma verrà prelevato dalla cima dello stack l’indirizzo di rientro del programma principale.
Lo stack pointer
Lo stack è una struttura dinamica, che cresce e diminuisce come abbiamo visto dagli esempi precedenti. Occorre allora un meccanismo per informare il microprocessore sulla posizione in cui si trova la cima dello stack. Questo meccanismo si basa su un registro del microprocessore che si chiama Stack pointer. Tale registro conterrà sempre l’indirizzo della cima dello stack.
Tabella 3
|
Indirizzo |
Locazione |
|
100 |
Vuoto |
|
101 |
Vuoto |
|
102 |
Vuoto |
|
103 |
Vuoto |
|
104 |
Vuoto |
Quando lo stack è vuoto lo SP contiene l’indirizzo 105. Se volgiamo inserire un dato nello stack esso andrà inserito nella locazione di memoria che si trova all’indirizzo formato dal contenuto dello SP –1 cioè 104
|
Indirizzo |
Locazione |
|
100 |
Vuoto |
|
101 |
Vuoto |
|
102 |
Vuoto |
|
103 |
Vuoto |
|
104 |
Primo dato |
Poiché lo stack è cresciuto, ora lo SP deve essere decrementato a 104. Un nuovo dato va inserito all’indirizzo SP-1 cioè 103
|
Indirizzo |
Locazione |
|
100 |
Vuoto |
|
101 |
Vuoto |
|
102 |
Vuoto
|
|
103 |
Secondo dato |
|
104 |
Primo dato |
LO SP viene portato a 103
Il terzo dato viene inserito all’indirizzo 102 e così via. Un meccanismo opposto si avrà quando i dati vengono prelevati.